My 1st undergraduate internship was spent at the London Regional Cancer Program (LCRP) at the London Health Sciences Centre (LHSC). During this term, I spent time calibrating and operating electron beam radiation therapy machines. Some of my time was spent irradiating radio-chromic gels using these machines and then analyzing images of these gels using MATLAB to get dosage measurements. I spent the rest of my time writing Python scripts to automate and streamline the creation of radiation treatment plans in the cancer centre’s treatment planning software. I also utilized Windows Presentation Foundation (WPF) and XAML to create and integrate custom GUIs into the Python scripts. This was my first exposure to writing software outside of course material, and I learned a lot about creating GUIs and working with new APIs.
My 2nd undergraduate internship was spent at the Multi-Scale Additive Manufacturing Lab. This is a research lab at the University of Waterloo that specialises in additive manufacturing, specifically additive manufacturing of metal parts. I worked with powder bed fusion (PBF) machines to 3D print metal parts and then acquired 3D scans of those parts using a CT scanner. I then wrote MATLAB code using the Image Processing Toolbox to process these 3D scans with the goal of analyzing the pore structure of these printed parts. This was my first exposure to the world of image processing, which led me down the long road of discovering computer vision, machine learning, and robotics.
My 3rd undergraduate internship was spent at the Communications Research Centre (CRC), which is a Government of Canada research lab focused on wireless communications. During this term, I worked with spatial cellular signal strength datasets. I trained random forests and fully-connected neural networks using TensorFlow and Scikit-Learn to perform spatial interpolation of the signal strengths, improving upon the baseline methods. I reduced error by 5% and smoothed the output maps by constructing rotational features in the dataset. I then created cellular signal strength data visualization tools with wxPython and the Google Maps Static API. This internship was my first exposure to machine learning, and provided me with useful insights on the importance of feature engineering.
My 4th undergraduate internship was spent at P&P Optica, a company in Waterloo that builds hyperspectral imaging systems to automatically detect contaminants in food passing on conveyer belts. Hyperspectral imaging systems are able to take images with a continuous wavelength dimension. This means that for each pixel, we are able to accurately determine the material by classifying the spectral signature using machine learning. While I was at P&P Optica, I spent some time working on the core Python pipeline that processes the hyperspectral image data to detect foreign contaminants in real time. This pipeline utilizes OpenCV and Scikit-Learn to work with and classify the input image stream. I then created an automatic ROI masking tool using spectral filtering and OpenCV, which was used to reduce data labeling times by up to 40%. I also built some hyperspectral image data visualization tools using unsupervised learning techniques in Scikit-Learn such as PCA, K-means, and DBSCAN. I ended the term by working on a project where I oversaw the collection of training datasets of vegetables at varying freshness levels, then used Scikit-Learn and TensorFlow to train SVMs and CNNs to classify the freshness of the vegetables. Overall, this was a very impactful internship, where I learned a lot about production machine learning and got to work on my first large-scale software stack.
My 5th and 6th undergraduate internships were spent at Huawei’s Noah’s Ark Lab, a research lab focused on AI. For both terms, I was with the autonomous vehicle perception research team. My first term with the team was spent working on advancing LiDAR object detection on the KITTI and nuScenes datasets. I worked with both PyTorch and TensorFlow to design and implement experiments for improving 3D detection performance. The architectures I was working with were similar to seminal architectures in LiDAR object detection, namely SECOND and PointPillars. While working on LiDAR object detection, I developed a few tools to aid the other researchers in analyzing their model predictions. I wrote a tool to visualize 3D object detection predictions on the KITTI dataset using Python with NumPy and VTK. I then wrote a Python tool to calculate useful statistics from the model predictions on different 3D object detection datasets. During my second term with the team, I led the development of a web app used for semantic labeling of LiDAR point clouds. This web app allows users to load in point clouds from a dataset, and then manually assign semantic class labels to each point in the point cloud by moving around and using painting tools in 3D space. This application was primarily built using JavaScript with Three.js. Overall, these two terms offered many challenges, but were definitely rewarding in the end. It was my first time working on state-of-the-art autonomous vehicle research, and I learned a lot about the space. My second term was also quite a challenge, since I had never used JavaScript or worked on any web apps before. However, this made the term even more rewarding in the end, since I was forced to adapt and learn a brand new skill.
My 7th undergraduate internship was spent at DarwinAI, a company specializing in using deep learning for visual quality inspection. DarwinAI was acquired by Apple in March 2024, likely to utilize their visual quality inspection technology for their own assembly lines. During my internship, I worked on a research project where my goal was to segment weld defects in X-Ray images using deep learning. I trained a U-Net to perform semantic segmentation of the weld defects on an X-Ray image dataset containing a total of 10 ultra high-resolution images. I developed novel methods to extract training data from those 10 images and experimented with training schemes to achieve a final test IoU of 50%. While I worked on the research project, I also lead the research and proof-of-concept implementation of an MLOps-based model training and deployment pipeline. The design was based on this MLOps pipeline and used PyTorch, Kubeflow, MLflow, and DVC.
In the summer before starting grad school I did an internship at OTTO Motors, which is a division of Clearpath Robotics (now owned by Rockwell Automation). OTTO Motors builds autonomous mobile robots (AMRs) for material handling in warehouses. Think of a pallet that can drive itself around warehouses to transport goods. I worked on the perception team, who’s job is to process the sensor inputs to estimate the robot’s current position as well as the state of its environment. I spent most of my term building a simulation pipeline to automatically generate training data for our perception models. I ended up using Unity to build a system that procedurally generates virtual warehouse environments, and then extracts training images along with their labels to create large training datasets for computer vision models. The labels extracted include bounding boxes, semantic and instance segmentation labels, as well as depth maps. To validate the effectiveness of the dataset, I trained YOLOv7 object detection models to perform forklift detection. Although the models trained stricly on the simulation datasets were useable, the real value came from using the simulation for pre-training. Pre-training a model on the simulation dataset then fine-tuning it on a small real-life dataset resulted in a 20% improvement in test mAP over fine-tuning from the default COCO weights.
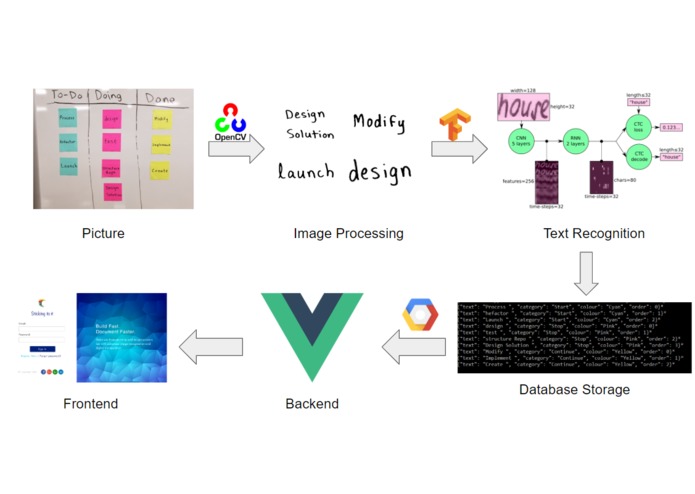
This hackathon project uses computer vision to digitize agile boards. I developed the computer vision code to extract individual post-it notes and then feed it to a trained text recognition model.
I led the computer vision division of the UW Robotics Team, a student team participating in an autonomous robot racing competition. We built software to process LiDAR data, as well as process camera data to detect and classify lane lines, stop lines, and traffic signs.
For this hackathon project, we built a video lip-reading pipeline for a smart glasses device. I built an inference pipeline to process a video stream and feed it to a trained lip-reading model. We ended up being one of the winning teams, achieving a 3rd place finish.
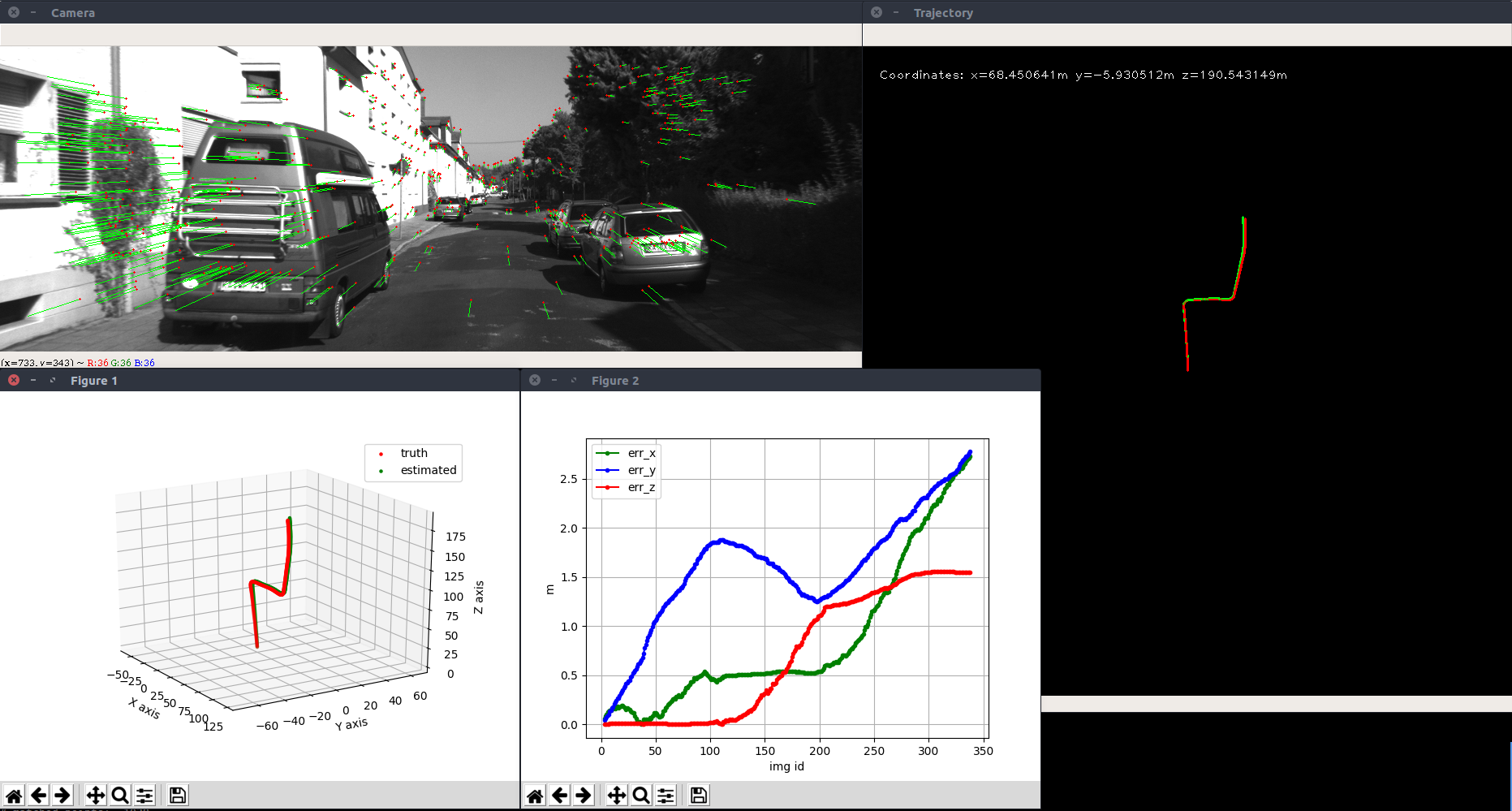
This is a recruitment challenge organized by comma.ai where the goal is to estimate the offset between the camera pose and ego heading given video input. This is a very small dataset, so pure machine learning solutions are not likely to generalize well. In the end, my solution utilized visual odometry based on feature tracking using OpenCV. I also trained a semantic segmentation model on the Comma10k dataset to filter out dynamic objects before feature extraction, which gave a 35% relative improvement over the original pipeline. Since this is a recruiting challenge, I’ve been asked by comma.ai to keep the solution code private.
I spent about 2.5 years in the perception division for WATonomous, a student team participating in the SAE AutoDrive Challenge. I spent time training models on custom datasets to do 3D dynamic object detection, lane detection, and 2D sign detection. I then pivoted to working on a research project, where we looked into sim2real domain adaptation for lane detection. This work resulted in a publication at IV2022. More information on the paper can be found in the Publications page.
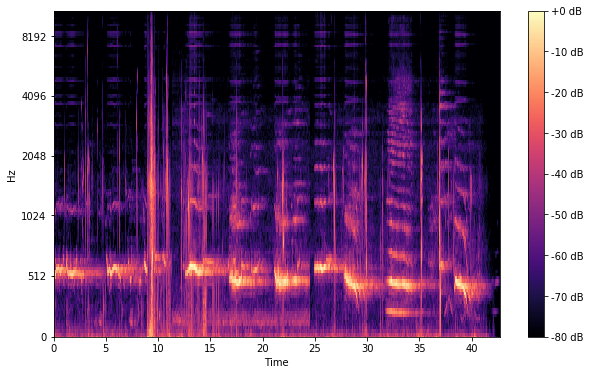
This project looks at classifying vocal percussion audio using machine learning. I explore two primary methods, feeding mel spectrograms to CNNs and feeding MFCC features to traditional ML methods, such as k-nearest neighbors and random forests.
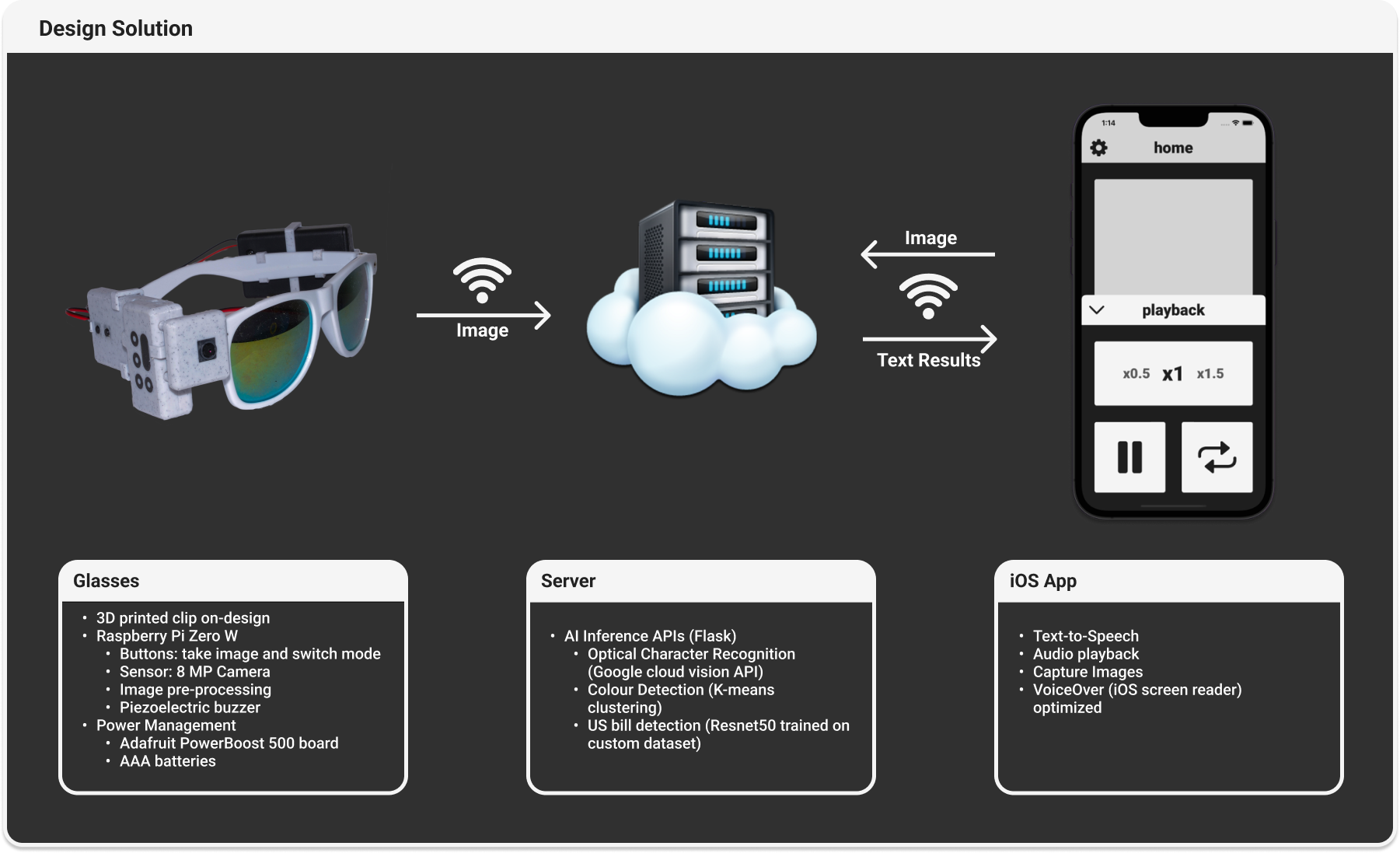
For my Fourth Year Design Project (FYDP), my team and I built a smart glasses device for the visually impaired. I spent most of my time building computer vision features to allow users to accomplish tasks using the camera on the device. The computer vision features included are OCR, color detection, and money classification. For OCR, I utilized the Google Cloud Vision API to return any text in the image. For color detection, I developed an algorithm that returns the nearest color in a database. For money classification, I collected a custom image dataset of different bills and trained a ResNet using PyTorch to classify the bills. We were awarded an Interdisciplinary Capstone Design Award for this project.
In this project, I was exploring training deep learning models for end-to-end planning through behavior cloning. I worked with the comma2k19 dataset, which contains video logs of 33 hours of driving as well as accurate GPS measurements of the car which can be converted into driving labels. I explored a lot of dataset preprocessing techniques in this project, namely for cleaning and selecting the data to train on. The main architecture I settled on is a CNN to encode individual frames, and an RNN variant to process the features from multiple frames. I also explored different prediction heads, such as simple regression, discretized classification, and mixture density networks.
In this project, I try using model predicting control (MPC) for planning on the highway-env simulator. Here I defined an MPC formulation that takes into account trajectory predictions for all other cars, and tries to optimize a plan that makes progress towards the goal while avoiding all other agents over the horizon. The issue with this formulation is the non-convexity of the collision check constraint, which makes the optimization very unstable.
Published in IEEE Intelligent Vehicles Symposium (IV), 2022
Recommended citation: Citation: Hu, C., Hudson, S., Ethier, M., Al-Sharman, M., Rayside, D., & Melek, W. (2022, June). Sim-to-real domain adaptation for lane detection and classification in autonomous driving. In 2022 IEEE Intelligent Vehicles Symposium (IV) (pp. 457-463). IEEE.
Published in Conference on Computer Vision and Pattern Recognition (CVPR), 2023
Recommended citation: Citation: Rowe, L., Ethier, M., Dykhne, E. H., & Czarnecki, K. (2023). FJMP: Factorized joint multi-agent motion prediction over learned directed acyclic interaction graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 13745-13755).