Projects
Individual project write-ups are coming soon! In the meantime, click on the project title to visit the project page or GitHub repo.
In this project, I try using model predicting control (MPC) for planning on the highway-env simulator. Here I defined an MPC formulation that takes into account trajectory predictions for all other cars, and tries to optimize a plan that makes progress towards the goal while avoiding all other agents over the horizon. The issue with this formulation is the non-convexity of the collision check constraint, which makes the optimization very unstable.

In this project, I was exploring training deep learning models for end-to-end planning through behavior cloning. I worked with the comma2k19 dataset, which contains video logs of 33 hours of driving as well as accurate GPS measurements of the car which can be converted into driving labels. I explored a lot of dataset preprocessing techniques in this project, namely for cleaning and selecting the data to train on. The main architecture I settled on is a CNN to encode individual frames, and an RNN variant to process the features from multiple frames. I also explored different prediction heads, such as simple regression, discretized classification, and mixture density networks.

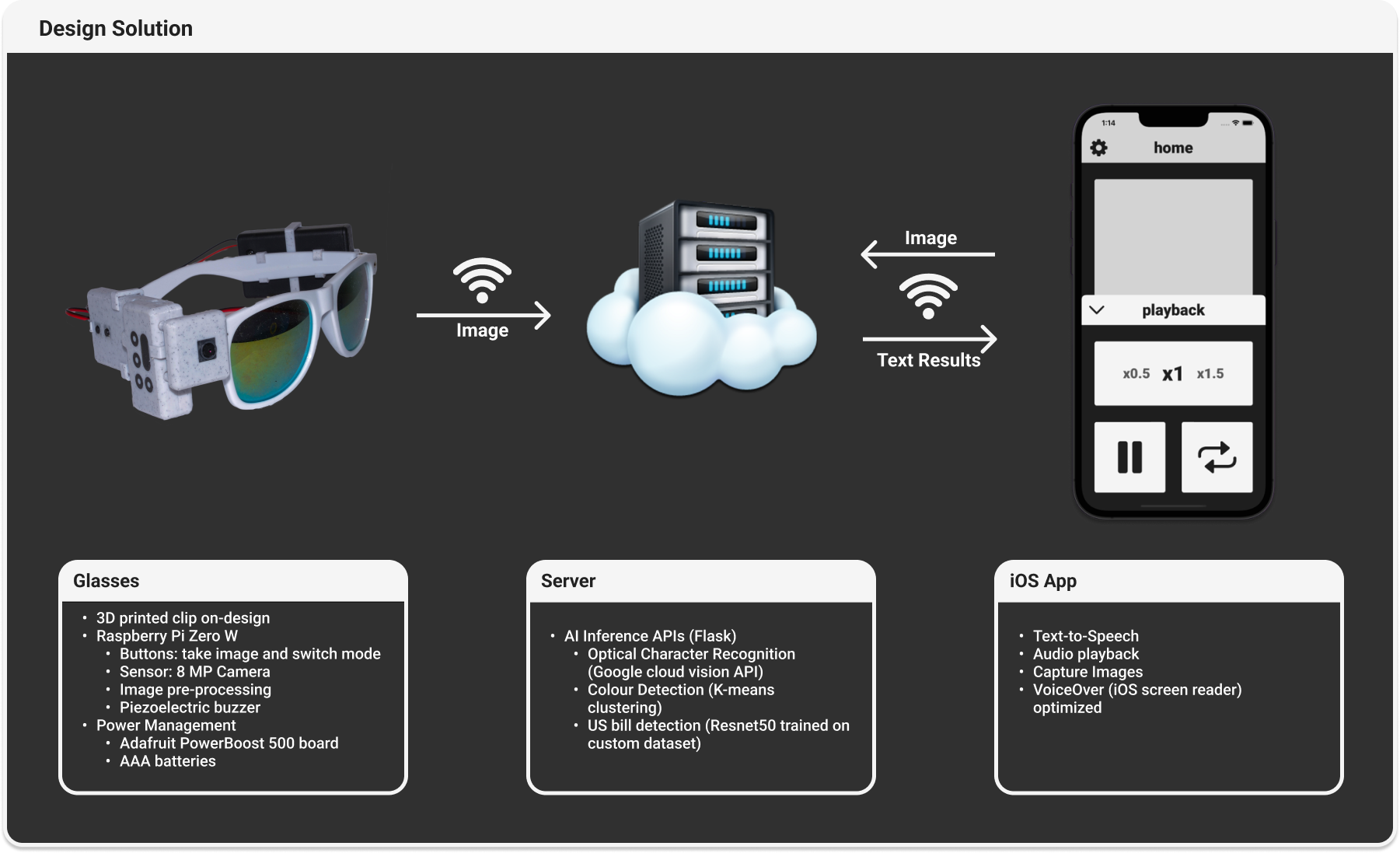
For my Fourth Year Design Project (FYDP), my team and I built a smart glasses device for the visually impaired. I spent most of my time building computer vision features to allow users to accomplish tasks using the camera on the device. The computer vision features included are OCR, color detection, and money classification. For OCR, I utilized the Google Cloud Vision API to return any text in the image. For color detection, I developed an algorithm that returns the nearest color in a database. For money classification, I collected a custom image dataset of different bills and trained a ResNet using PyTorch to classify the bills. We were awarded an Interdisciplinary Capstone Design Award for this project.
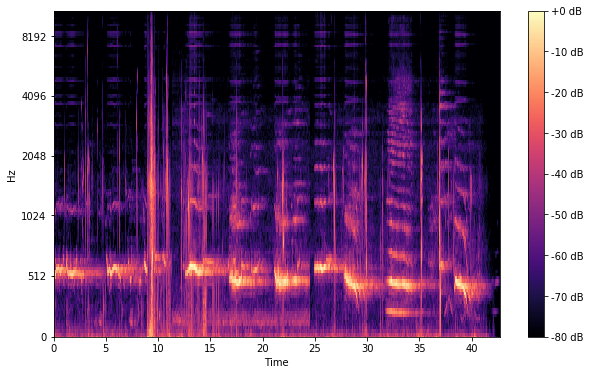
This project looks at classifying vocal percussion audio using machine learning. I explore two primary methods, feeding mel spectrograms to CNNs and feeding MFCC features to traditional ML methods, such as k-nearest neighbors and random forests.
I spent about 2.5 years in the perception division for WATonomous, a student team participating in the SAE AutoDrive Challenge. I spent time training models on custom datasets to do 3D dynamic object detection, lane detection, and 2D sign detection. I then pivoted to working on a research project, where we looked into sim2real domain adaptation for lane detection. This work resulted in a publication at IV2022. More information on the paper can be found in the Publications page.

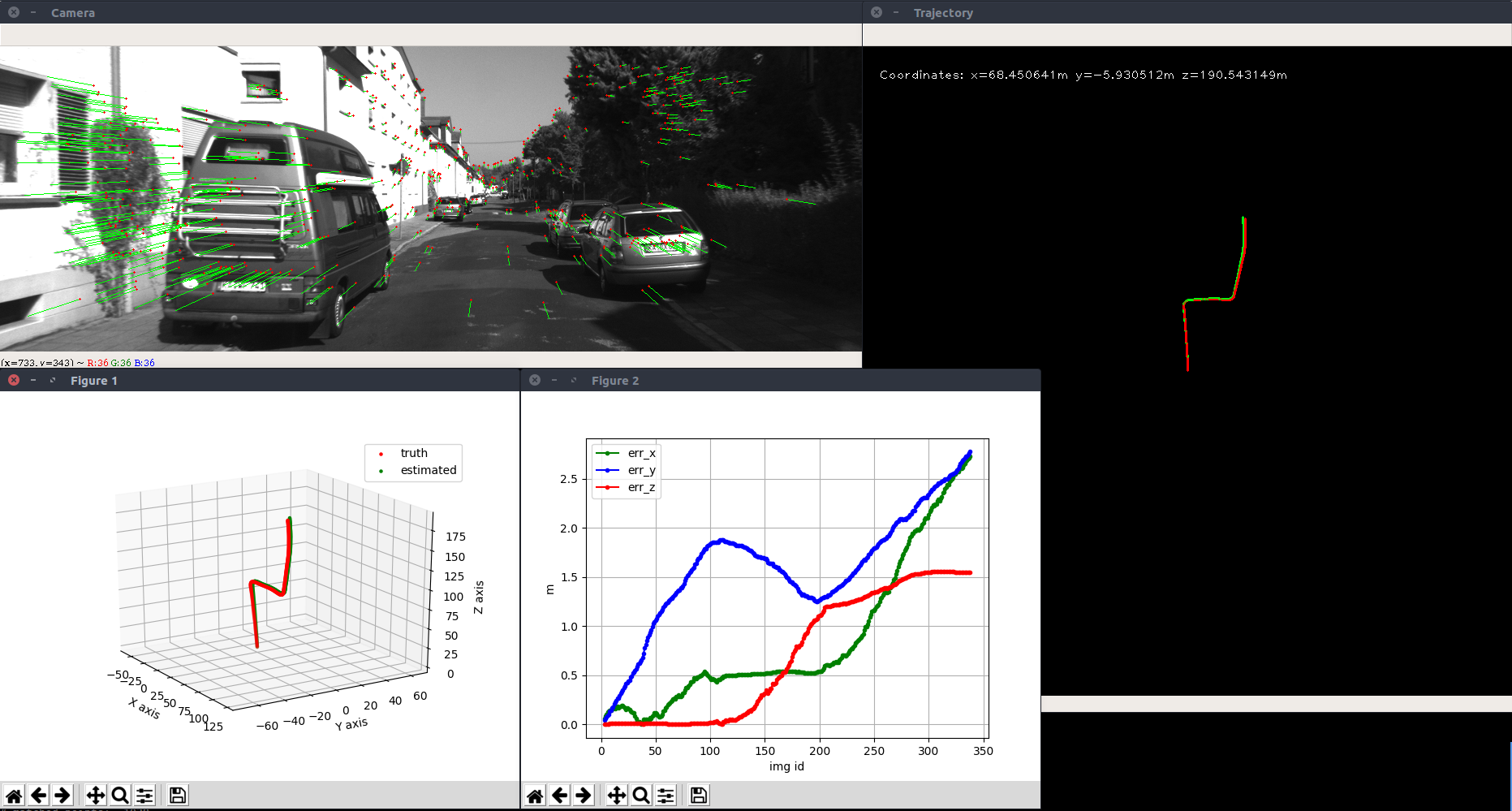
This is a recruitment challenge organized by comma.ai where the goal is to estimate the offset between the camera pose and ego heading given video input. This is a very small dataset, so pure machine learning solutions are not likely to generalize well. In the end, my solution utilized visual odometry based on feature tracking using OpenCV. I also trained a semantic segmentation model on the Comma10k dataset to filter out dynamic objects before feature extraction, which gave a 35% relative improvement over the original pipeline. Since this is a recruiting challenge, I’ve been asked by comma.ai to keep the solution code private.
For this hackathon project, we built a video lip-reading pipeline for a smart glasses device. I built an inference pipeline to process a video stream and feed it to a trained lip-reading model. We ended up being one of the winning teams, achieving a 3rd place finish.

I led the computer vision division of the UW Robotics Team, a student team participating in an autonomous robot racing competition. We built software to process LiDAR data, as well as process camera data to detect and classify lane lines, stop lines, and traffic signs.

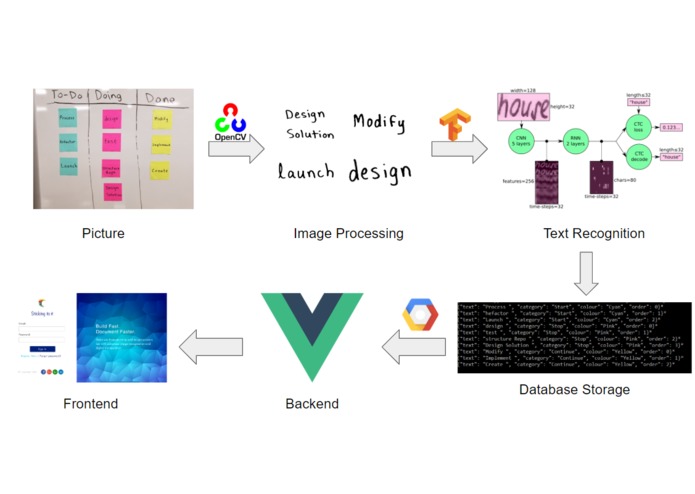
This hackathon project uses computer vision to digitize agile boards. I developed the computer vision code to extract individual post-it notes and then feed it to a trained text recognition model.